Case Study
The Product That Built Itself
A product built to orchestrate parallel AI agents — developed entirely with itself. Here's what that actually looks like, and what we learned.
The Problem
AI made coding faster.
It made coordination harder.
Our team was already deep into AI-assisted development — running Claude Code, Gemini, Amazon Q, and others daily. The individual productivity gains were real. The workflow around them was not.
Each agent session lived in its own terminal window with its own working directory, its own context, and zero awareness of what the others were doing. To run two experiments simultaneously, you opened two terminals. To compare outputs, you copy-pasted between them. When an agent went down a bad path, you manually rolled back and started over — while the other sessions sat idle.
The bottleneck wasn't code generation anymore. It was coordination.
Worse, the tools weren't designed to talk to each other. You could make any single agent faster — but the friction between sessions compounded with every new one you added. Four parallel sessions didn't give you 4x throughput. They gave you a management problem.
The Shift
From running agents to orchestrating them
"We didn't need better prompts. We needed a system that could hold multiple agents, multiple branches, and multiple outcomes at the same time — without us manually stitching them together."
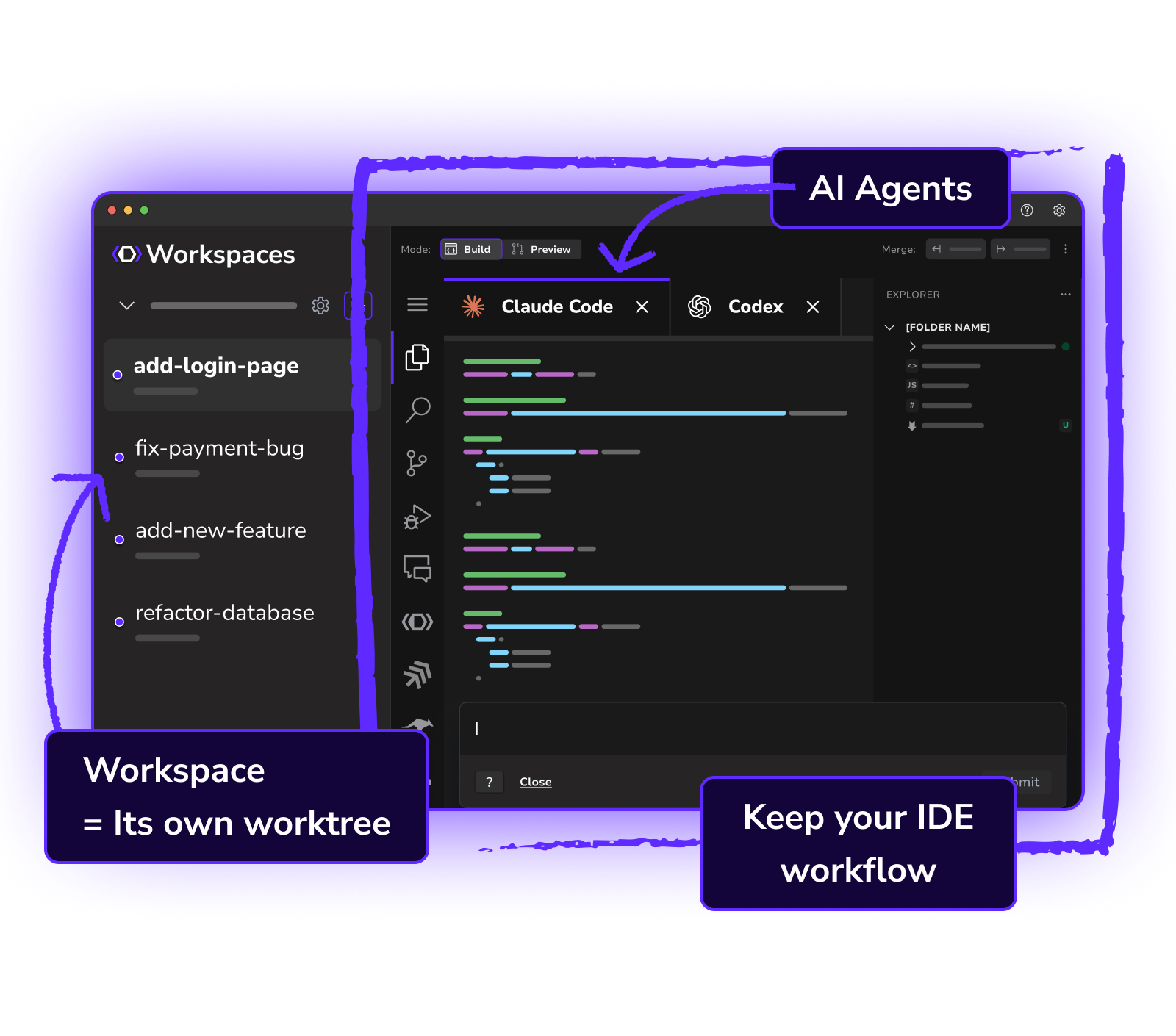
The insight was architectural. Each AI agent needed its own isolated environment — not just a separate terminal session, but a separate Git worktree. Real filesystem isolation. Its own branch. Its own runtime. No shared state that could corrupt another agent's work.
With that in place, you could run five agents on the same feature request and get five genuinely independent implementations. Then you evaluate and merge the best one. That changed the shape of the work entirely.
Git Worktree Isolation
Every workspace gets its own Git worktree — a real, separate working directory on disk. No branch conflicts. No shared state corruption between agents.
Agent-Agnostic
Works with Claude Code, Amazon Q, OpenAI Codex, Gemini, and 20+ others. Swap the model without changing the workflow. The orchestration layer is independent of the underlying AI.
Side-by-Side Review
Compare diffs, terminal output, and editor state across all active workspaces before deciding which path to merge. Decisions become explicit, not accidental.
The Origin
DevSwarm wasn't designed.
It was discovered.
The first version wasn't a product. It was an internal experiment — a rough setup that let us run multiple AI agents in parallel on separate Git worktrees, then review and merge the best result.
Each workspace operated independently: its own environment, its own context, its own task. No agent knew what the others were doing. We compared results manually. The moment that changed how quickly we could evaluate and ship, we knew it was more than a personal productivity trick.
The tool we were building was the tool we needed to build it.
Define a task
A feature, a bug fix, an experiment, a refactor. DevSwarm fans it out across multiple isolated workspaces — each one gets the task, nothing else is shared.
Agents explore in parallel
Each workspace runs an AI agent inside its own Git worktree, with its own terminal, editor, and runtime state. Agents can't interfere with each other.
Review side by side
Compare code diffs, terminal output, and editor state across all workspaces simultaneously. The review is intentional — not a rubber stamp on whatever finished first.
Merge the best result
Choose the winning approach and merge. Discard the others. Every decision is deliberate, with full context.
The Meta-Story
Building DevSwarm with DevSwarm
As the system stabilized, we started using it to build itself — not as a demo, but as our actual production workflow.
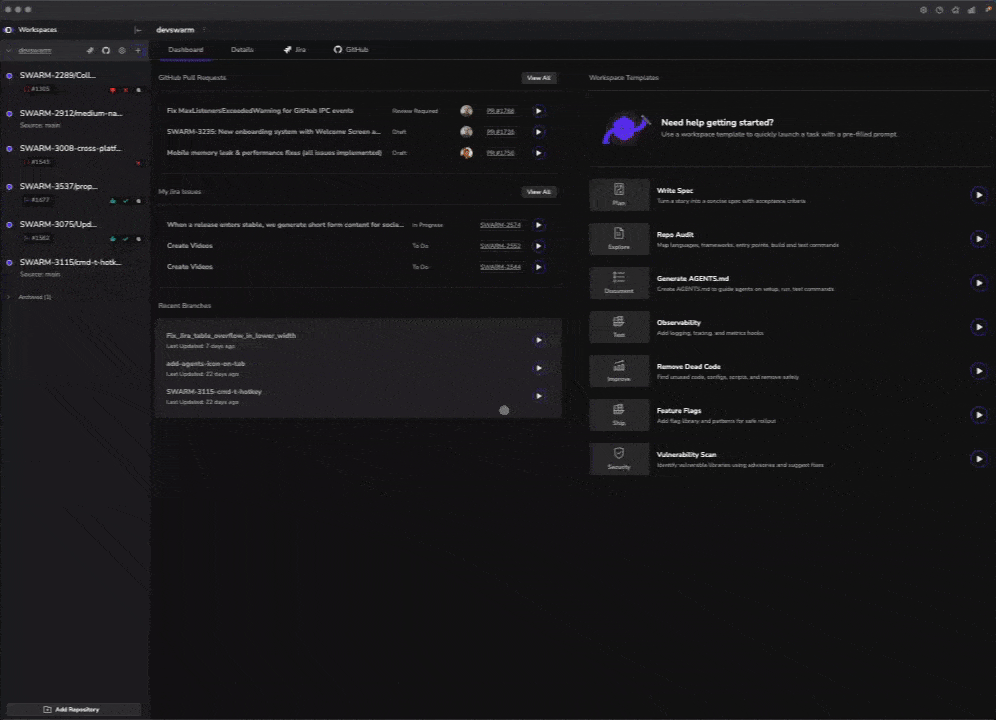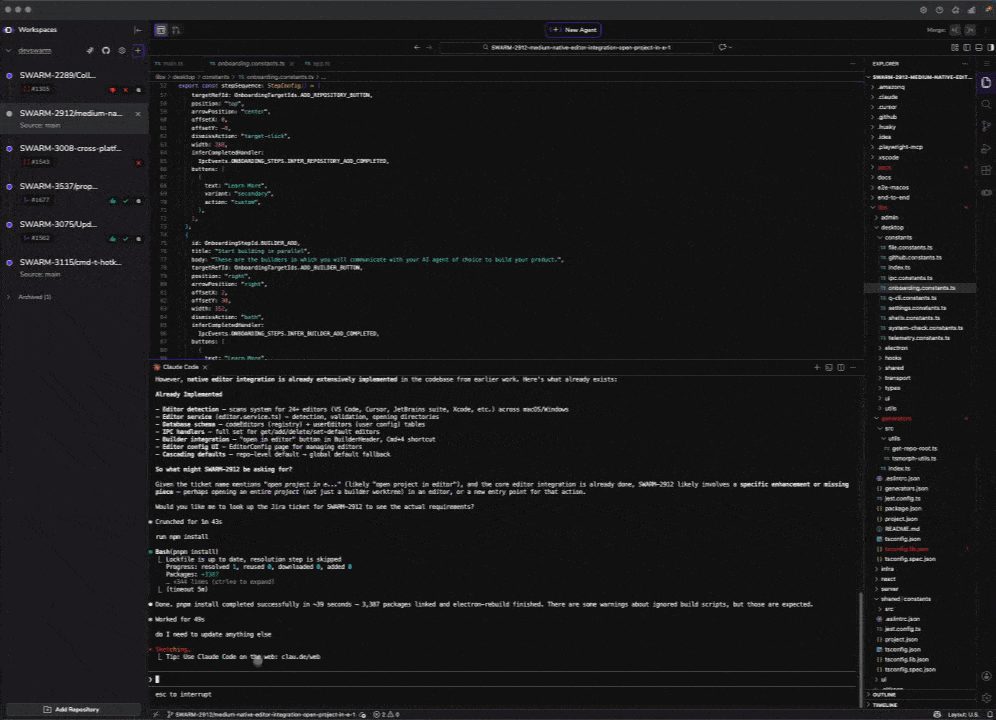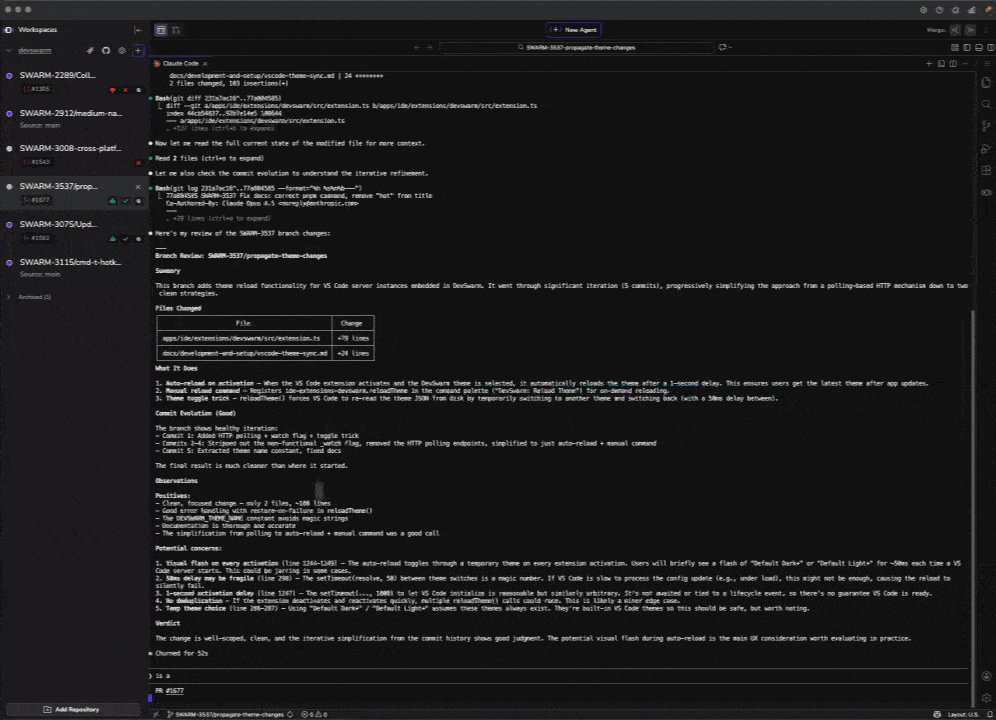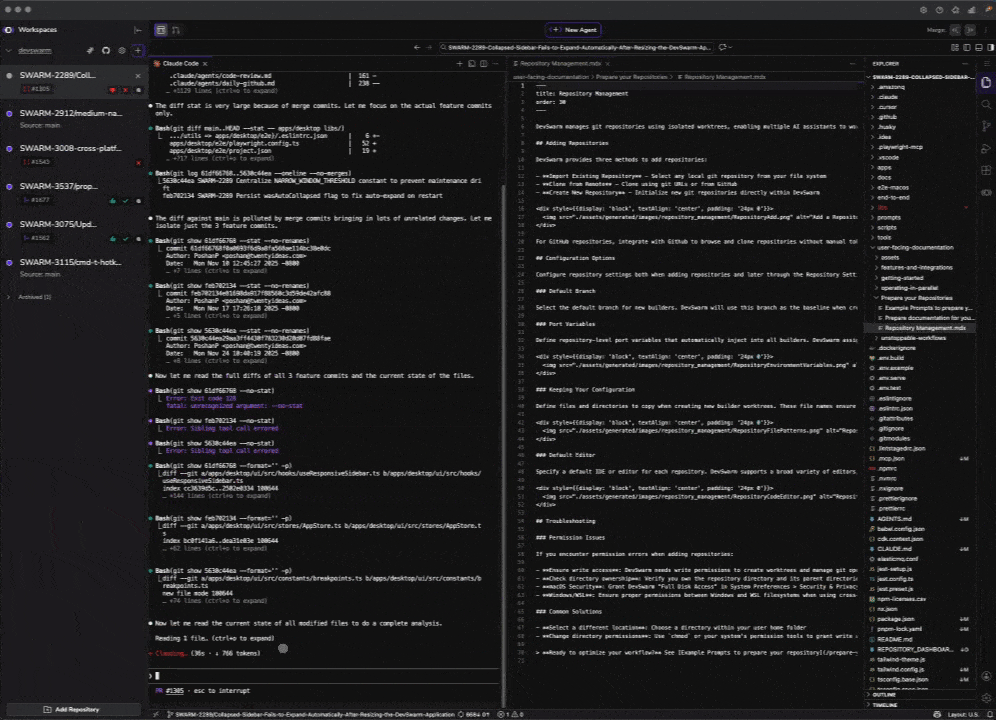
DevSwarm is an Nx monorepo with 15+ packages: an Electron main process, a React renderer, a CLI, a shared component library, shared types, transport layers, infrastructure-as-code, a static marketing site, and more. At any given time, we had workspaces open on the Electron side, the UI, and the marketing site simultaneously — all agents running, all branches isolated.
We weren't waiting for one thing to finish before starting the next. We were evaluating outcomes in parallel. A feature that would have taken a sequential team a full day — spec, implement, review, ship — could complete multiple implementation cycles before we'd normally be done with the first draft.
The constraint shifted from "how fast can we write code?" to "how fast can we make good decisions?"
The Results
Before vs. After
The difference wasn't subtle, and it wasn't about raw speed. It was about what kind of work became possible at all.
- One terminal per agent, no shared visibility across sessions
- Manual branch creation and switching between experiments
- Context switching killed momentum — finishing one thread meant losing another
- Comparing agent outputs required manual copy-paste between windows
- Idle time waiting for one task to finish before starting the next
- Agent drift: long sessions accumulated bad context with no clean reset
- All active workspaces visible in one dashboard — status, output, diffs
- Git worktrees provisioned automatically per workspace, zero setup
- Multiple experiments run simultaneously; you evaluate, not wait
- Side-by-side diff review before any merge decision
- Jira and GitHub integrated — tasks flow directly into workspace context
- Clean workspace state on every session — agents start fresh, every time
The Insight
The real unlock:
decision velocity
Most AI tools are designed to help you write code faster. DevSwarm is designed for something different: giving you more options to choose from, faster, with full context on each one.
When you can run five implementations in parallel and evaluate them side by side, "What's the best solution?" becomes an empirical question instead of a guess. You stop debating approaches and start comparing them.
That shift has a compounding effect. Better decisions made faster, consistently, across every feature and every bug fix — that's where the real productivity multiplier lives. Not in faster typing.
"We stopped asking 'What's the best way to build this?' and started asking 'Let's try four ways — and choose the best one.' That reframe changed everything about how we ship."
Hard Lessons
Where it broke — and what we actually learned
This wasn't magic. Every problem we solved with parallelism surfaced a new category of problem we hadn't anticipated. AI doesn't remove complexity — it redistributes it. Here's what bit us.
Agent context drift
Long-running sessions accumulate bad context. An agent that starts sharp can go sideways after an hour of accumulated back-and-forth. We learned to treat workspace sessions as short-lived: fresh context, clean state, every time. DevSwarm's architecture enforces this by design.
Parallelism multiplies decisions, not just outputs
Running five agents gives you five results — but it also means you now have to evaluate five results. The bottleneck shifted from generation to review. We had to deliberately design review workflows, not assume that "more outputs" automatically meant "better outcomes."
Shared state is the enemy
Early versions let agents share a SQLite database, which caused locking failures under concurrent writes. Git worktrees solved the branch isolation problem, but every other shared resource — DBs, build caches, config files — had to be isolated too. Isolation is not just a Git concern.
Structure has to come before speed
Moving fast with multiple agents without strong architecture produces incoherent codebases fast. We formalized our own internal standards — dependency injection patterns, IPC conventions, service boundaries — before scaling the number of active agents. You can't review your way out of a structureless codebase.
The Evolution
From terminal scripts
to full IDE
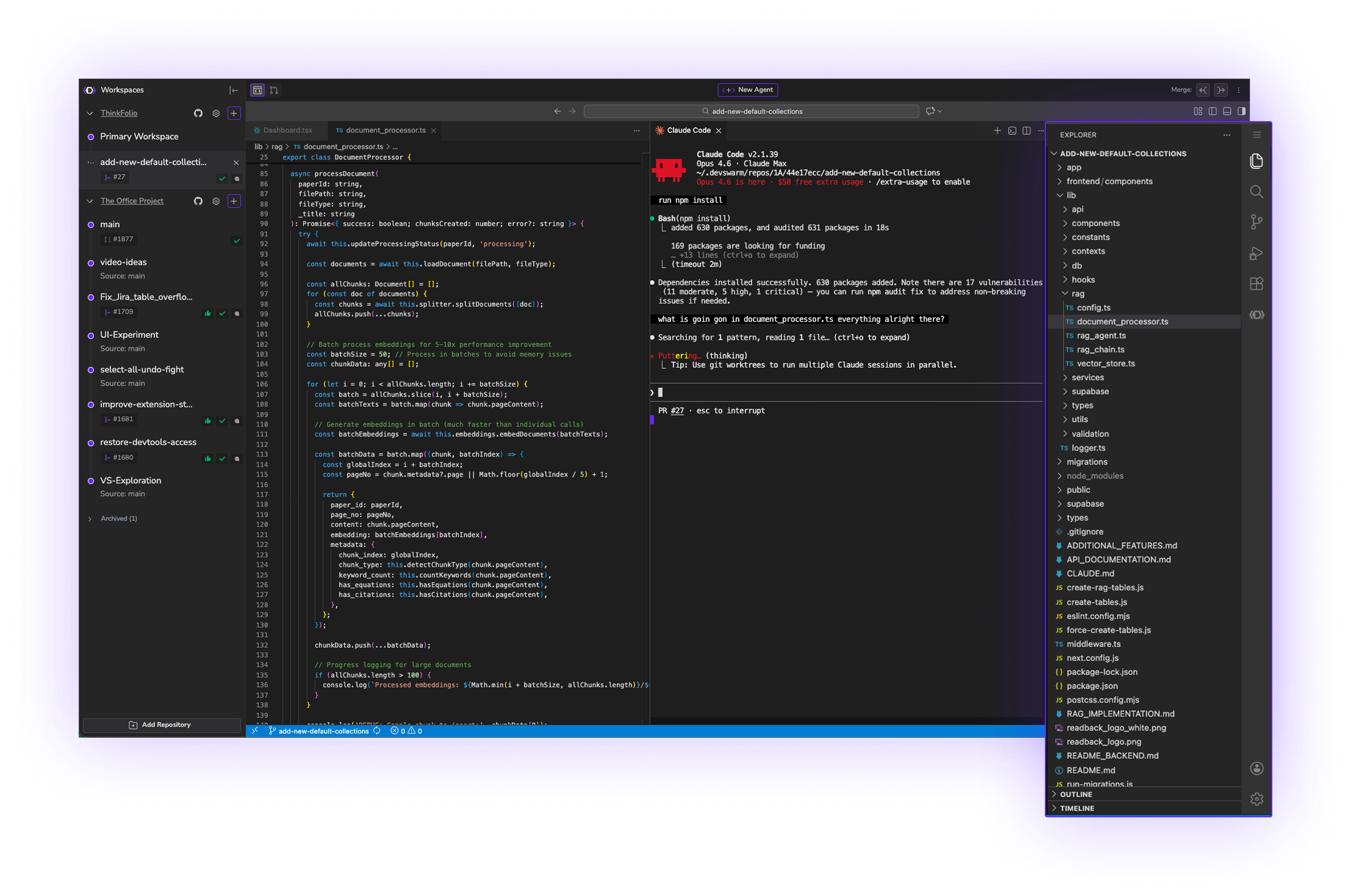
Early DevSwarm was shell scripts and tmux panes. It was enough to prove the model — multiple agents, isolated branches, manual comparison. But the friction of leaving the environment to inspect anything compounded fast.
Every code review meant switching to a separate editor. Every diff meant opening a terminal. Every merge meant context-switching out of the flow entirely. So we rebuilt it.
DevSwarm evolved into a full IDE: integrated terminal (built on xterm.js), VS Code integration via the open-source VS Code server, a built-in diff viewer, an agent panel, and a Jira/GitHub integration that brings task context directly into the workspace. No tab-switching. No lost threads. One environment for the full development cycle.
We also built a CLI — the devswarm command — so workspace management works from the terminal for teams that prefer it. The desktop app and CLI share the same underlying service layer.
The Philosophy
HiVE — not vibe
"Vibe coding" — prompting an AI and shipping whatever comes back — produces demos. It doesn't produce production systems. The things that matter in production — correctness, security, maintainability, coherent architecture — don't emerge automatically from faster generation. They require judgment, structure, and deliberate decision-making. DevSwarm was built around a different model.
Move Fast
Parallel workspaces compress exploration time. What used to be a sequential process — try one approach, evaluate, backtrack, try another — becomes simultaneous. Multiple paths, same clock.
Maintain Structure
Every agent runs in full isolation. Every architectural decision is explicit — enforced through DI patterns, typed IPC contracts, and review gates. Structure is what makes speed safe to use.
Humans Evaluate, Not Rubberstamp
AI generates. Humans decide. The system is designed to surface options, not bury the developer in outputs. The review step is the product, not an afterthought.
Why It Matters
Built under real
production pressure.
DevSwarm wasn't designed in a whiteboard session about "the future of AI development." It was built because we couldn't work the old way anymore. Every constraint in the product came from a real problem we hit — usually mid-sprint, on a real deadline, in a real codebase with real complexity.
The worktree isolation came from watching agents corrupt each other's work. The review workflow came from discovering that faster generation doesn't help if you can't evaluate outputs quickly. The integrated IDE came from losing 20 minutes a day switching contexts.
We used DevSwarm to build DevSwarm through every iteration — the Electron backend, the React UI, the CLI, the marketing site, the infrastructure. If a feature made us slower, it didn't ship. If a workflow created friction, we fixed it. The product is shaped by that feedback loop in a way that no amount of user research can replicate.
DevSwarm isn't a tool we built and handed off. It's how we build. Still, today.
The future of development
isn't faster generation
It's better orchestration. AI can produce code at scale — but building real products still requires judgment, structure, and decision-making at speed. DevSwarm gives you a system for that.
You're not adopting a new tool. You're adopting a system that's been stress-tested — on a real, complex, production codebase. Ours.